

One of BeeHero’s core customer values is the ability to indicate the strength of a hive without sending a beekeeper to directly inspect it. For large scale pollination and beekeeping this is crucial - you simply can’t inspect all the hives, as a pollination season will require hundreds of thousands of hives. But even sampling these hives takes a toll on the bees (and the beekeepers) as interrupting the hive by opening it for inspection has a negative effect on the bees׳ activity.
We deliver the hive strength indicator through our ground breaking prediction models, which process the IoT sample and infer a prediction for the number of bee frames a hive holds, the number of brood frames, the likelihood of the hive collapsing and other key indicators.
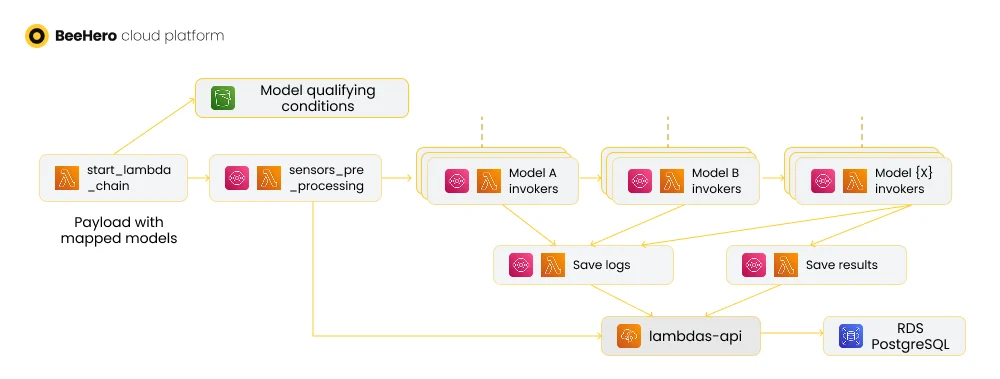
The model inferences are executed on a schedule, and require preparing the payload for the inference and then executing the models in sequential order (as some of the inference results are used as input for other models)
This is where our ‘lambda chain’ comes in - our initial approach to running the inferences. It was composed of a lambda that triggered the process, then a second lambda that prepared the payload, a third lambda to map which inference models should run for each payload, then a succession of inference executions, and finally a lambda to save the results.
Each lambda in the chain ‘knew’ about the next lambda to run, and accumulated the results into the payload sent to the next lambda in the chain.
We also supported ‘silent’ models - running inference and saving their results as logs, but not as customer-facing values. This allowed us to experiment with model development and contrast and compare results between various models with the same input.
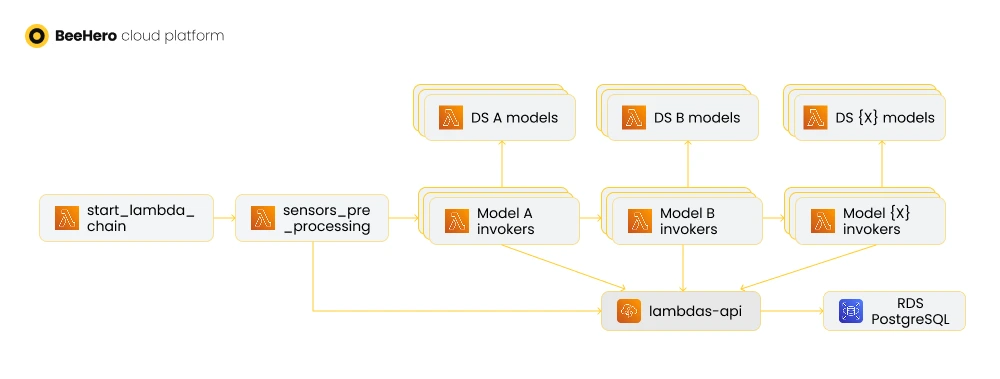
This approach worked well while BeeHero established its technology, but when we scaled our operations and started accumulating millions of samples a day, our lambda chain started to struggle as well:
To gain better control and coordination in our ‘lambda chain’ we first introduced AWS SQS queues into the chain. Instead of triggering the lambdas in the chain directly, we added a queue for each lambda and triggered the lambda by messages sent to the queue. Each lambda worked the same as before, but instead of invoking the next lambda with a synchronous API call, it sent the accumulated sensor payload to the queue of the next lambda.
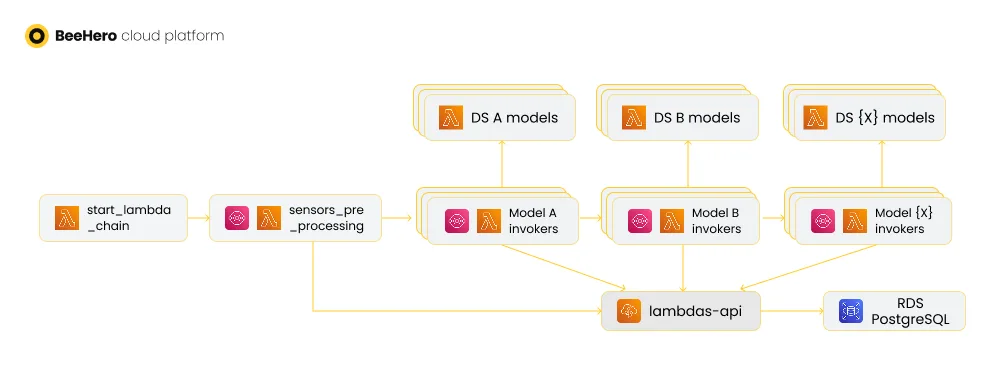
Using queues allowed us to streamline the API calls. First and foremost, SQS triggers support batching and concurrency, which enabled us to control how many lambdas are invoked simultaneously. Configuring the trigger’s concurrency setting limits the number of concurrent lambdas, which had two results: a limit on the number of concurrent API calls, and better usage of ‘warm start’. Configuring the batch setting allowed each lambda to be more efficient in handling sensors, especially in API server calls (which also supported batches of sensors) and in invoking the SQS API sending messages to the next queue (which is much more efficient when sending batches of messages).
The ‘warm start’ further reduced the number of concurrent AWS Parameter Store API calls, as the invocations on the same execution environment could share a global state and we saved the parameters to this global state.
Next, all the ‘silent’ model results were consolidated into a single lambda that engaged with the API server - all the model execution lambdas sent messages to this lambda instead of invoking the API server directly. The ‘saving’ lambda concurrency and batch properties allowed for efficient API calls with minimal timeouts. Removing the dependency on the API server in model execution lambdas also simplified their execution and made it more reliable at scale.
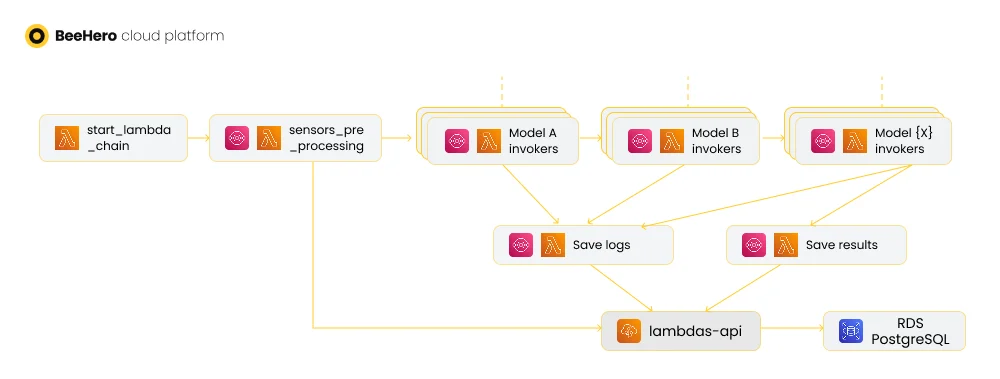
Finally, retries and error handling were much improved. SQS message failures can be managed in partial batch replies, so that you don’t need to run the whole batch again - instead, only the failed messages are returned to the queue for retry. You can set the retries limit as usual, but when a message hits the max number of retries, it goes to a deadletter queue (DLQ) which in turn can be monitored and alert us when a message didn’t go through the chain - and then we can research the issue, fix if needed, and manually redrive the DLQ messages to try again.
‘Model serving’ is the process of deploying and invoking a trained data science model for customer-facing inferences. Our ‘lambda chain’ started off with a very simple serving - we run all the models for all the sensors. But as we scaled and introduced more variance to our data and customers, we needed to be more agile - for example, some models were trained for a specific geography or specific seasonality, and should only be invoked for sensors of the same conditions.
To support these emerging requirements, we introduced a mapping mechanism where our data science team could map inference models to sensor qualifiers. We debated different options for a standard way to define these qualifiers: JSON-based custom definitions, python code and SQL. We decided to go with SQL ‘WHERE’ clauses, as it neatly tied in with how we kicked off the ‘lambda chain’ - with a query on a DB View consolidating the list of sensors that qualify for inference. The mapped conditions could be just applied as part of the query to produce a list of sensors for each inference model.
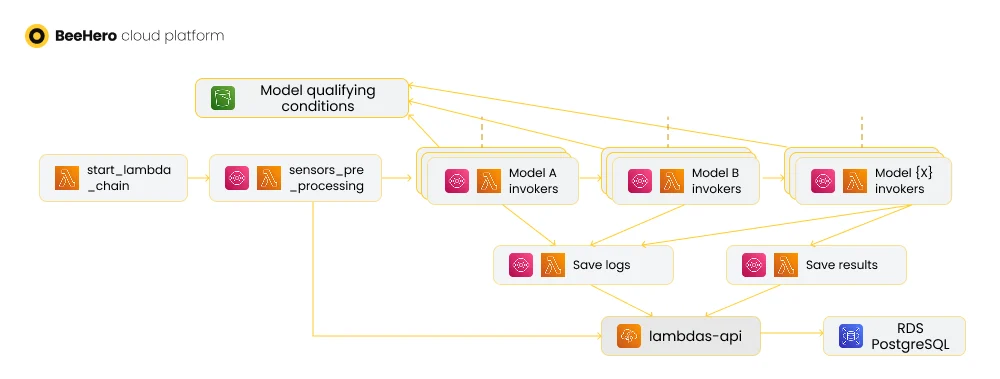
Once we had this mapping in place, we could apply it early in our lambda chain - in fact, right on start. By loading all the various inference mappings at the chain start, we could calculate in advance which inference models should run for each sensor, and include it as part of the sensor payload, so that subsequent model execution lambdas could just pull this information and invoke the right inference, without wasting additional time on loading the mapping and figuring out to which model the sensor maps. Since the model execution lambdas are the ones that scale out in proportion to the increasing number of sensors, every optimization of their run time was beneficial.
Queues, batches, concurrency and smart serving supported our pollination seasons nicely, and streamlined execution of our lambda chain. But there was still much to be desired in terms of our end-to-end MLOps - for example, our data science team started working with a new model which required lengthy calculations of features. We started to pay more attention on how to scale our data science processes - but we will get back to this in a future post…


